Welcome Frictionless Framework (v5)
By Evgeny Karev on 2022-08-22 » Blog Index
We're releasing a first beta of Frictionless Framework (v5)!Since the initial Frictionless Framework release we'd been collecting feedback and analyzing both high-level users' needs and bug reports to identify shortcomings and areas that can be improved in the next version for the framework. Once that process had been done we started working on a new v5 with a goal to make the framework more bullet-proof, easy to maintain and simplify user interface. Today, this version is almost stable and ready to be published. Let's go through the main improvements we have made:
Improved Metadata
This year we started working on the Frictionless Application, at the same time, we were thinking about next steps for the Frictionless Standards. For both we need well-defined and an easy-to-understand metadata model. Partially it's already published as standards like Table Schema and partially it's going to be published as standards like File Dialect and possibly validation/transform metadata.
Dialect
In v4 of the framework we had Control/Dialect/Layout concepts to describe resource details related to different formats and schemes, as well as tabular details like header rows. In v5 it's merged into the only one concept called Dialect which is going to be standardised as a File Dialect spec. Here is an example:
header: true
headerRows: [2, 3]
commentChar: '#'
csv:
delimiter: ';'
from frictionless import Dialect, Control, formats
dialect = Dialect(header=True, header_rows=[2, 3], comment_char='#')
dialect.add_control(formats.CsvControl(delimiter=';'))
print(dialect)
A dialect descriptor can be saved and reused within a resource. Technically, it's possible to provide different schemes and formats settings within one Dialect (e.g. for CSV and Excel) so it's possible to create e.g. one re-usable dialect for a data package. A legacy CSV Dialect spec is supported and will be supported forever so it's possible to provide CSV properties on the root level:
header: true
delimiter: ';'
from frictionless import Dialect, Control, formats
dialect = Dialect.from_descriptor({"header": True, "delimiter": ';'})
print(dialect)
For performance and codebase maintainability reasons some marginal Layout features have been removed completely such as skip/pick/limit/offsetFields/etc. It's possible to achieve the same results using the Pipeline concept as a part of the transformation workflow.
Read an article about Dialect Class for more information.
Checklist
Checklist is a new concept introduced in v5. It's basically a collection of validation steps and a few other settings to make "validation rules" sharable. For example:
checks:
- type: ascii-value
- type: row_constraint
formula: id > 1
skipErrors:
- duplicate-label
from frictionless import Checklist, checks
checklist = Checklist(
checks=[checks.ascii_value(), checks.row_constraint(formula='id > 1')],
skip_errors=['duplicate-label'],
)
print(checklist)
Having and sharing this checklist it's possible to tune data quality requirements for some data file or set of data files. This concept will provide an ability for creating data quality "libraries" within projects or domains. We can use a checklist for validation:
frictionless validate table1.csv --checklist checklist.yaml
frictionless validate table2.csv --checklist checklist.yaml
Here is a list of another changes:
| From (v4) | To (v5) |
|---|---|
| Check(descriptor) | Check.from_descriptor(descriptor) |
| check.code | check.type |
Read an article about Checklist Class for more information.
Pipeline
In v4 Pipeline was a complex concept similar to validation Inquiry. We reworked it for v5 to be a lightweight set of validation steps that can be applied to a data resource or a data package. For example:
steps:
- type: table-normalize
- type: cell-set
fieldName: version
value: v5
from frictionless import Pipeline, steps
pipeline = Pipeline(
steps=[steps.table_normalize(), steps.cell_set(field_name='version', value='v5')],
)
print(pipeline)
Similar to the Checklist concept, Pipeline is a reusable (data-abstract) object that can be saved to a descriptor and used in some complex data workflow:
frictionless transform table1.csv --pipeline pipeline.yaml
frictionless transform table2.csv --pipeline pipeline.yaml
Here is a list of another changes:
| From (v4) | To (v5) |
|---|---|
| Step(descriptor) | Step.from_descriptor(descriptor) |
| step.code | step.type |
Read an article about Pipeline Class for more information.
Resource
[email protected] this experimental feature (resource.checklist/pipeline) has been disabled to conform better with the standards.
There are no changes in the Resource related to the standards although currently by default instead of profile the type property will be used to mark a resource as a table. It can be changed using the --standards v1 flag.
It's now possible to set Checklist and Pipeline as a Resource property similar to Dialect and Schema:
path: table.csv
# ...
checklist:
checks:
- type: ascii-value
- type: row_constraint
formula: id > 1
pipeline: pipeline.yaml
steps:
- type: table-normalize
- type: cell-set
fieldName: version
value: v5
Or using dereference:
path: table.csv
# ...
checklist: checklist.yaml
pipeline: pipeline.yaml
In this case the validation/transformation will use it by default providing an ability to ship validation rules and transformation pipelines within resources and packages. This is an important development for data publishers who want to define what they consider to be valid for their datasets as well as sharing raw data with a cleaning pipeline steps:
frictionless validate resource.yaml # will use the checklist above
frictionless transform resource.yaml # will use the pipeline above
There are minor changes in the stats property. Now it uses named keys to simplify hash distinction (md5/sha256 are calculated by default and it's not possible to change for performance reasons as it was in v4):
from frictionless import describe
resource = describe('table.csv', stats=True)
print(resource.stats)
Here is a list of another changes:
| From (v4) | To (v5) |
|---|---|
| for row in resource: | for row in resource.row_stream |
Read an article about Resource Class for more information.
Package
There are no changes in the Package related to the standards although it's now possible to use resource dereference:
name: package
resources:
- resource1.yaml
- resource2.yaml
Read an article about Package Class for more information.
Catalog
[email protected] this experimental feature is changes and now it requires catalog.datasets[].package structure.
Catalog is a new concept that is a collection of data packages that can be written inline or using dereference:
name: catalog
packages:
- package1.yaml
- package2.yaml
Read an article about Catalog Class for more information.
Detector
Detector is now a metadata class (it wasn't in v4) so it can be saved and shared as other metadata classes:
from frictionless import Detector
detector = Detector(sample_size=1000)
print(detector)
Read an article about Detector Class for more information.
Inquiry
There are few changes in the Inquiry concept which is known for using in the Frictionless Repository project:
| From (v4) | To (v5) |
|---|---|
| inquiryTask.source | inquiryTask.path |
| inquiryTask.source | inquiryTask.resource |
| inquiryTask.source | inquiryTask.package |
Read an article about Inquiry Class for more information.
Report
The Report concept has been significantly simplified by removing the resource property from reportTask. It's been replaced by name/type/place/labels properties. Also report.time is now report.stats.seconds. The report/reportTask.warnings: List[str] have been added to provide non-error information like reached limits:
frictionless validate table.csv --yaml
Here is a list of changes:
| From (v4) | To (v5) |
|---|---|
| report.time | report.stats.seconds |
| reportTask.time | reportTask.stats.seconds |
| reportTask.resource.name | reportTask.name |
| reportTask.resource.profile | reportTask.type |
| reportTask.resource.path | reportTask.place |
| reportTask.resource.schema | reportTask.labels |
Read an article about Report Class for more information.
Schema
Changes in the Schema class:
| From (v4) | To (v5) |
|---|---|
| Schema(descriptor) | Schema.from_descriptor(descriptor) |
Error
There are a few changes in the Error data structure:
| From (v4) | To (v5) |
|---|---|
| error.code | error.type |
| error.name | error.title |
| error.rowPosition | error.rowNumber |
| error.fieldPosition | error.fieldNumber |
Types
Note that all the metadata entities that have multiple implementations in v5 are based on a unified type model. It means that they use the type property to provide type information:
| From (v4) | To (v5) |
|---|---|
| resource.profile | resource.type |
| check.code | check.type |
| control.code | control.type |
| error.code | error.type |
| field.type | field.type |
| step.type | step.type |
The new v5 version still supports old notation in descriptors for backward-compatibility.
Improved Model
It's been many years that Frictionless were mixing declarative metadata and object model for historical reasons. Since the first implementation of datapackage library we used different approaches to sync internal state to provide both interfaces descriptor and object model. In Frictionless Framework v4 this technique had been taken to a really sophisticated level with special observables dictionary classes. It was quite smart and nice-to-use for quick prototyping in REPL but it was really hard to maintain and error-prone.
In Framework v5 we finally decided to follow the "right way" for handling this problem and split descriptors and object model completely.
Descriptors
In the Frictionless World we deal with a lot of declarative metadata descriptors such as packages, schemas, pipelines, etc. Nothing changes in v5 regarding this. So for example here is a Table Schema:
fields:
- name: id
type: integer
- name: name
type: string
Object Model
The difference comes here we we create a metadata instance based on this descriptor. In v4 all the metadata classes were a subclasses of the dict class providing a mix between a descriptor and object model for state management. In v5 there is a clear boundary between descriptor and object model. All the state are managed as it should be in a normal Python class using class attributes:
from frictionless import Schema
schema = Schema.from_descriptor('schema.yaml')
# Here we deal with a proper object model
descriptor = schema.to_descriptor()
# Here we export it back to be a descriptor
There are a few important traits of the new model:
- it's not possible to create a metadata instance from an invalid descriptor
- it's almost always guaranteed that a metadata instance is valid
- it's not possible to mix dicts and classes in methods like
package.add_resource - it's not possible to export an invalid descriptor
This separation might make one to add a few additional lines of code, but it gives us much less fragile programs in the end. It's especially important for software integrators who want to be sure that they write working code. At the same time, for quick prototyping and discovery Frictionless still provides high-level actions like validate function that are more forgiving regarding user input.
Static Typing
One of the most important consequences of "fixing" state management in Frictionless is our new ability to provide static typing for the framework codebase. This work is in progress but we have already added a lot of types and it successfully pass pyright validation. We highly recommend enabling pyright in your IDE to see all the type problems in-advance:
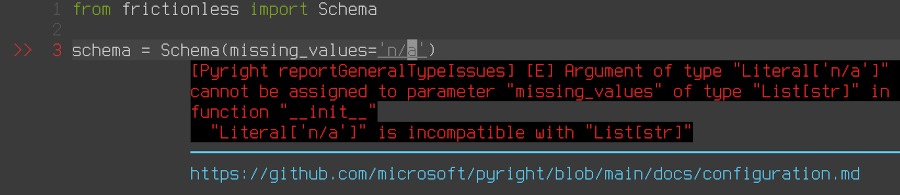
Livemark Docs
We're happy to announce that we're finally ready to drop a JavaScript dependency for the docs generation as we migrated it to Livemark. Moreover, Livemark's ability to execute scripts inside the documentation and other nifty features like simple Tabs or a reference generator will save us hours and hours for writing better docs.
Script Execution
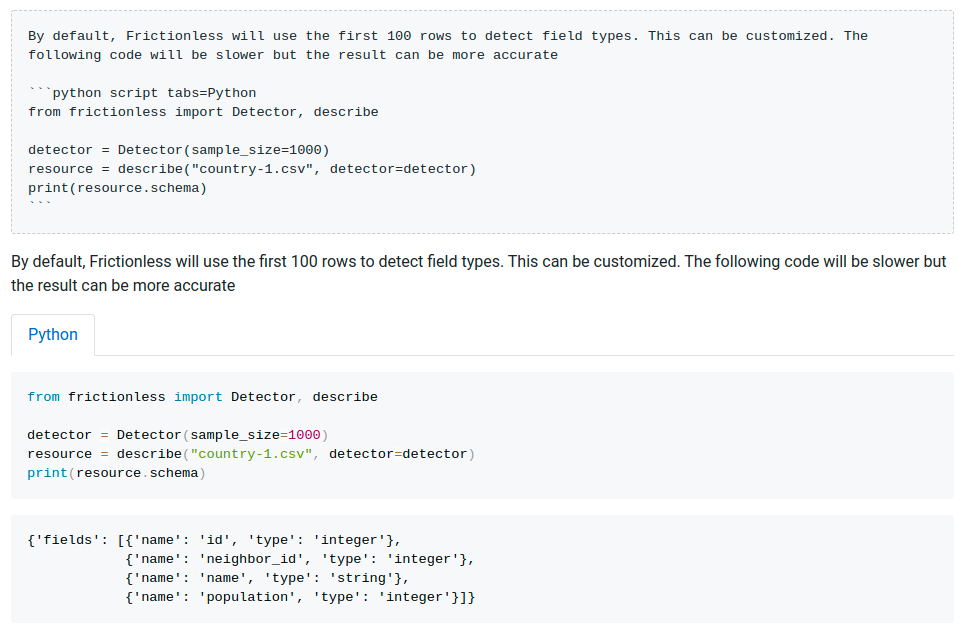
Reference Generation
Happy Contributors
We hope that Livemark docs writing experience will make our contributors happier and allow to grow our community of Frictionless Authors and Users. Let's chat in our Slack if you have questions or just want to say hi.
Read Livemark Docs for more information.